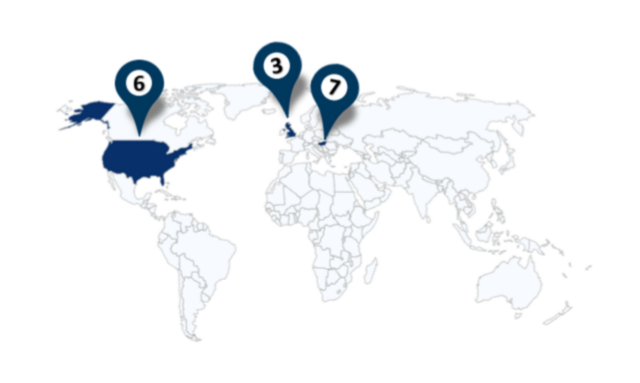
Global Reach
Consulting Experience Worldwide
16+ companies and 55+ completed projects across biotech and life science sectors internationally.
PhD
Transforming complex biological data into reliable, reproducible, and decision-ready results for biotech and life science companies worldwide.
Global Reach
16+ companies and 55+ completed projects across biotech and life science sectors internationally.
Work
Reproducible bioinformatics and data science — from raw data to final results, with full transparency at every step.
Dockerized environments, AWS cloud computing, and Quarto notebooks for fully transparent, verifiable workflows.
End-to-end RNA-seq and high-throughput sequencing — QC, statistical analysis, publication-ready figures.
Snakemake pipelines, automated reporting, and client-ready outputs with custom branding.
R Shiny dashboards with PostgreSQL integration for real-time, client-facing data exploration.
Regression and classification models with robust validation strategies and interpretable outputs.
Hypothesis testing, inferential statistics, and high-quality publication-ready visualizations in R.
01 — Reproducible Analysis
Transforming raw data into reliable results is a journey where the process matters as much as the outcome. My analyses are fully reproducible, with every step clearly documented. I use dockerized environments to ensure consistent execution, cloud computing (e.g. AWS) for scalable and secure computation, and Quarto R notebooks to combine code, results, and documentation into a single HTML report.
02 — NGS
I provide end-to-end analysis of NGS data, transforming raw sequencing outputs into biologically meaningful results. My work covers RNA-seq and other high-throughput sequencing data — data processing, quality control, statistical analysis, and clear, publication-ready visualizations. I emphasize reproducible workflows and transparent methodology throughout.
03 — Automation
I design automated, reproducible workflows using Snakemake, ensuring scalability, traceability, and reproducible execution across local, server, and HPC environments. I also build fully automated reporting pipelines that generate client-ready reports in HTML or PDF format, customized with company branding and consistent visual identity.
04 — Visualization
I develop interactive visualization solutions using R Shiny — custom web applications that allow dynamic interaction through responsive dashboards, plots, and tables. These applications can connect directly to PostgreSQL databases, enabling real-time data access without manual data exports.
05 — ML
I apply machine learning techniques to model complex relationships, make predictions, and extract actionable insights. My work focuses on regression and classification approaches within reproducible, well-documented workflows. I identify key drivers and patterns in data and assess model performance using robust validation strategies.
06 — Statistics
Rigorous statistical analysis using R — exploratory data analysis, hypothesis testing, descriptive and inferential statistics, and high-quality, publication-ready visualizations. I place strong emphasis on methodological soundness, reproducibility, and clarity, ensuring analyses are reliable and accessible to diverse audiences.
Background
I am an independent bioinformatics and data science consultant with a strong foundation in molecular biology and more than 10 years of wet-lab experience. This dual background allows me to understand biological questions, experimental design, and data limitations from a practitioner's perspective.
I have contributed to 40+ peer-reviewed publications in leading journals (Nature Medicine, Science, Nature Communications, Cancers, and Scientific Reports), and am a co-inventor on two patents, reflecting long-term involvement in scientific research and innovation.
I work closely with biotech and life science teams, offering direct communication, flexibility, and end-to-end involvement — from project scoping and data analysis to visualization, reporting, and knowledge transfer.
For a full list of publications, see my ORCID or Google Scholar profile.
Publications & Patents
Core Technologies
Domain Background
Trusted By
Partnering with biotech and life science teams across Europe and beyond.
Testimonials
Whenever we need customized solutions, from analysis of measurement data through fine tuning of R scripts to visualizations, we keep turning and returning to Krisztián.
Working with Krisztian on our NGS and sequencing data at Treos Bio was a genuinely great experience, he combines exceptional speed and flexibility with a thoughtful, constructive approach. His ability to turn complex data into clear, actionable insights made a real difference for our team and kept projects moving forward with confidence.
Krisztián provided excellent support in the analysis of clinical study data, enabling us to go beyond conventional statistical approaches and incorporate machine learning methods into our analytical workflows. His domain expertise and clear, accessible explanations made the collaboration highly efficient and effective.